Han Wu 吴瀚
Ph.D. Student @ ShanghaiTech
I am a Ph.D. student at the School of Biomedical Engineering, ShanghaiTech University, advised by Prof. Dinggang Shen. I obtained my B.Eng. with honors from Wuhan University of Technology in 2022.
During the initial stage of my Ph.D. (Sept. 2022 - June 2024), I focused on digital dentistry, working closely with Prof. Zhiming Cui. Since 2024, my research interest has shifted toward computer-aided cardiovascular disease diagnosis and treatment. Currently, I am also a research intern at United Imaging Intelligence (UII), working with Dr. Dijia Wu.

Ph.D. Student @ ShanghaiTech
My research focuses on developing intelligent, data-driven systems for computer-aided diagnosis and treatment in healthcare, with particular emphasis on cardiovascular and dental applications. My work centers on two core technical areas:
Education
ShanghaiTech University, Shanghai, China
Ph.D. in Computer Science
Sept. 2022 - Present
Supervisor: Prof. Dinggang Shen

Wuhan University of Technology, Wuhan, China
B.E. in Information Engineering
Sept. 2018 - June 2022
Outstanding Graduates (Postgraduate-Recommendation)

Experience
United Imaging Intelligence, Shanghai, China
Research Intern @ R&D
June 2025 - Present
Working with Dr. Dijia Wu.

News
- 05/2026One paper is early accepted by MICCAI 2026!
- 12/2025One paper is accepted by IEEE TMI, a nice ending for 2025!
- 07/2025One paper is accepted by IEEE TMI!
- 07/2025One paper is accepted by MedIA!
- 06/2025One paper is accepted by MICCAI 2025 after rebuttal!
- 06/2025Start my Research Intern @ UII, PASSION for CHANGE!
- 05/2025One clinical paper is accepted by Journal of Dentistry!
- 05/2025One paper is early accepted by MICCAI 2025!
- 05/2025My Google Scholar citations have reached 100! 🎈🎈🎈
- 03/2025One paper is accepted by MedIA!
- 10/2024One paper is accepted by IEEE TMI!
Publications
* indicates equal contribution and + indicates corresponding author.
Cardiovascular
4




Digital Dentistry
5





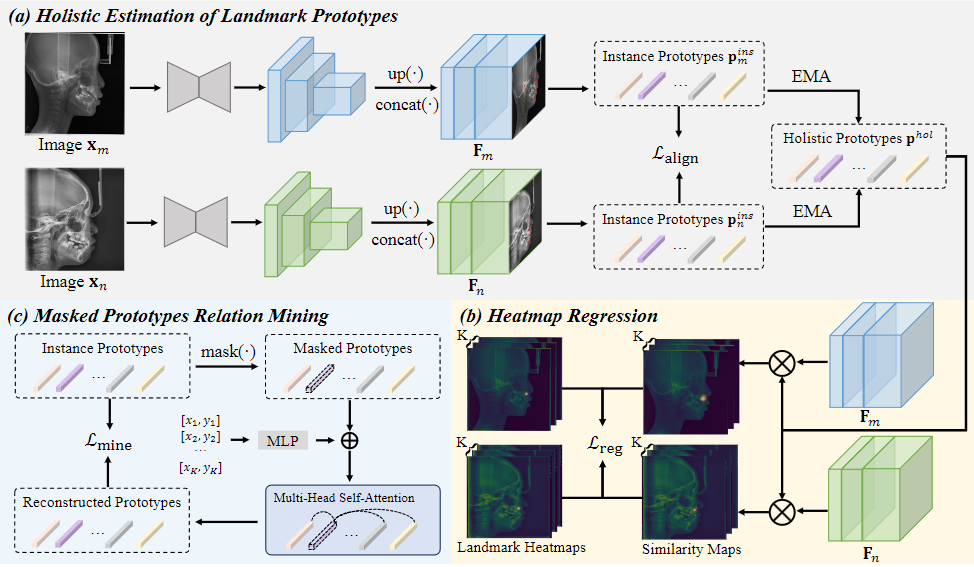

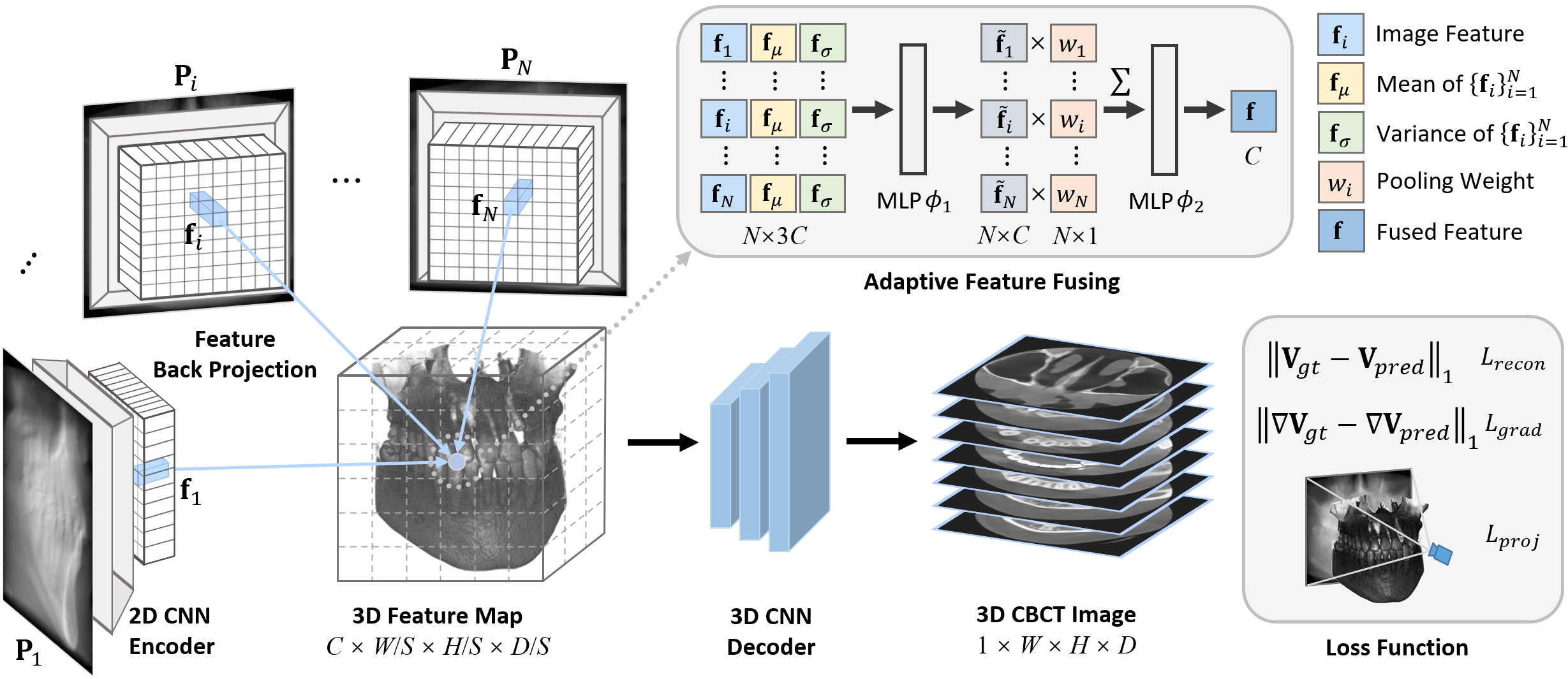

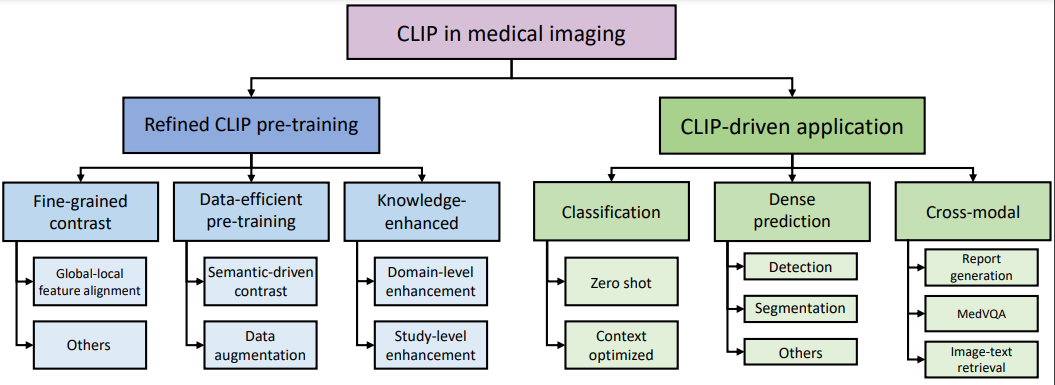

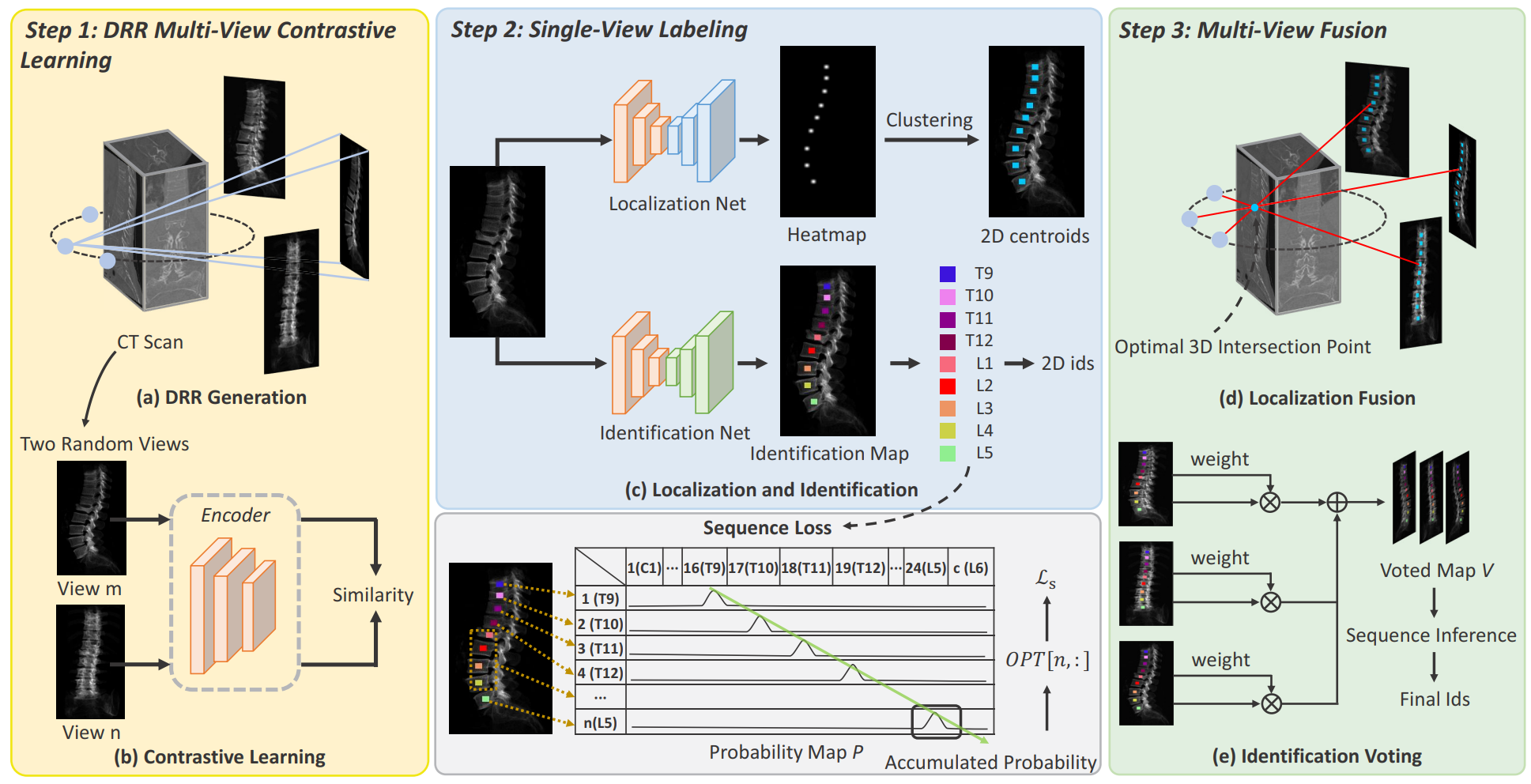

Preprint
Awards
- Outstanding Student of ShanghaiTech (Top 10%), 2023.
- Outstanding Graduates of WUT, 2022.
- Outstanding Graduation Thesis of WUT (top 4%), 2022.
- 2nd National Prize of National Undergraduate Engineering Practice and Innovation Competition, 2021.
- 3rd National Prize of The 10th "China Software Cup" College Student Software Design Competition, 2021.
- 1st Prize of Undergraduate Engineering Practice and Innovation Competition Hubei Prov., 2021.
- 3rd Prize of National University Student Intelligent Car Race, Hubei Prov., 2021.
- 3rd Prize of National Undergraduate Computer Design Competition, Hubei Prov., 2021.
- Ranked 27/169 in The 10th "China Software Cup" College Student Software Design Competition Online Tournament, 2021.
- 3rd Prize of The 6th "Internet+" Innovation and Entrepreneurship Competition, Hubei Prov., 2020.
- Ranked 3/218 in National University Student Intelligent Car Race Online Tournament: Crowd Counting, 2020.
- Ranked 15/332 in Baidu AIStudio Regular Season of Bugs Detection, 2020.
Services
Conference Reviewers
Journal Reviewers
- Neural Networks
- Signal Processing
- Digital Signal Processing
- IEEE Transactions on Medical Imaging (IEEE TMI)
- IEEE Transactions on Biomedical Engineering (IEEE TBME)
- IEEE Transactions on Geoscience and Remote Sensing (IEEE TGRS)
- ACM Transactions on Multimedia Computing Communications and Applications (ACM TOMM)
Membership
Teaching Assistant
- BME2113 Algorithms Design And Analysis (Python) @ ShanghaiTech, 2023 Fall
Other Services
- BaiDu PaddlePaddle Developer Expert (PPDE)
Invited Talks
AI in Digital Dentistry
Knowledge-driven Landmark Detection in Medical Images
Miscellaneous
Contact
wuhan2022 [at] shanghaitech.edu.cn
Address
393 Middle Huaxia Road, Pudong, Shanghai, China
Office
IDEA Lab @ BME Building, ShanghaiTech University, Shanghai, China